Parallel Scaling: Worker Count vs Pass Rate#
Date: 2026-02-24 Specs: 118 gold-standard (1 skipped — import error) Browser: Firefox (headless) Runs per config: 2
Context#
The original A/B experiment compared codegen baseline (15.3% pass rate) against gold-standard tests run sequentially with 1 worker. After completing the A/B comparison, we tested whether increasing Playwright’s worker count affected pass rates or introduced contention-related flakiness.
Results#
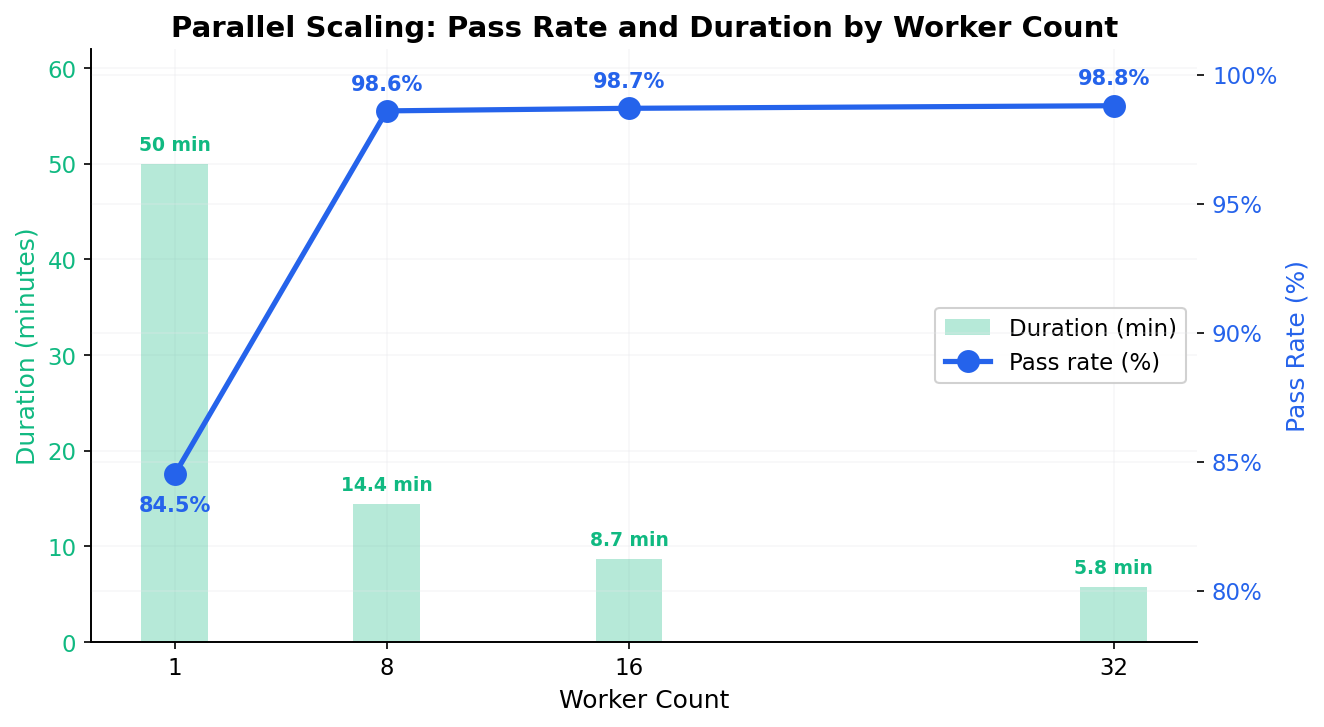
Summary by Worker Count#
Workers |
Avg Pass Rate |
Avg Failures |
Avg Duration |
Speedup vs 1w |
|---|---|---|---|---|
1 |
84.5% |
18.5 files |
~50 min |
— |
8 |
98.6% |
9.5 tests |
14.4 min |
~3.5x |
16 |
98.7% |
9.0 tests |
8.7 min |
~5.7x |
32 |
98.8% |
8.5 tests |
5.8 min |
~8.6x |
Detailed Run Data#
Sequential Baseline (1 worker) — per spec file#
Workers |
Run |
Passed |
Failed |
Skipped |
Total |
Pass Rate |
Duration |
|---|---|---|---|---|---|---|---|
1 |
Run 1 |
98 |
21 |
— |
119 |
82.4% |
~50+ min |
1 |
Run 2 |
103 |
16 |
— |
119 |
86.6% |
~50+ min |
Parallel Results — per individual test#
Workers |
Run |
Passed |
Failed |
Skipped |
Total (non-skipped) |
Pass Rate |
Duration |
|---|---|---|---|---|---|---|---|
8 |
Run 1 |
699 |
10 |
34 |
709 |
98.6% |
876s (14.6 min) |
8 |
Run 2 |
701 |
9 |
33 |
710 |
98.7% |
850s (14.2 min) |
16 |
Run 1 |
709 |
7 |
27 |
716 |
99.0% |
512s (8.5 min) |
16 |
Run 2 |
698 |
11 |
34 |
709 |
98.4% |
534s (8.9 min) |
32 |
Run 1 |
698 |
9 |
36 |
707 |
98.7% |
352s (5.9 min) |
32 |
Run 2 |
705 |
8 |
30 |
713 |
98.9% |
343s (5.7 min) |
Key Findings#
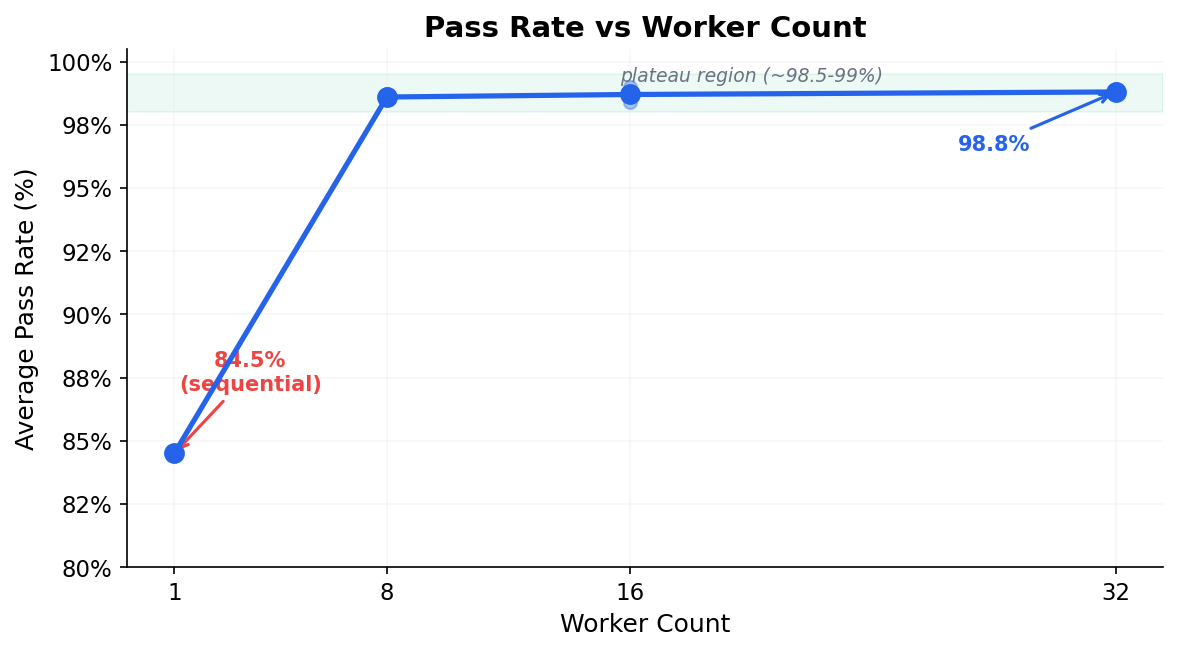
Pass rates plateau at ~98.5–99% regardless of worker count (8, 16, 32). Parallelism does not introduce flakiness.
Sequential runs are the outlier. The 1-worker pass rate (84.5%) is significantly lower than all parallel configurations. Likely cause: longer total runtime increases exposure to network timeouts, session expiry, and server-side state drift.
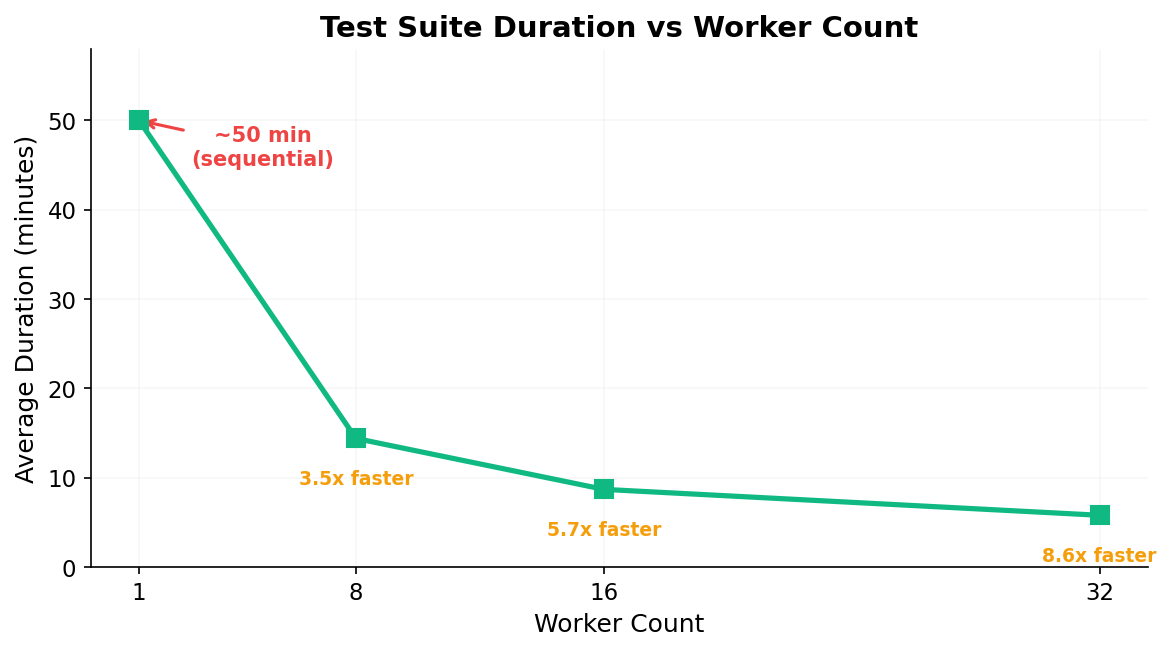
Duration scales roughly linearly with worker count: 50 min → 14 min → 8.5 min → 5.8 min. Diminishing returns begin around 32 workers for 118 specs.
Failures are stable across all configurations. The same ~9 tests fail regardless of parallelism — these are known issues (missing demo data, non-existent routes, environment-specific problems), not resource contention.
Measurement difference: Sequential counts at the spec-file level (1 file = 1 pass/fail), parallel counts at the individual test level. This makes direct numerical comparison imprecise, but the trend is unambiguous.